
Document Parsing and Question Answering with LLMs Served Locally
Published:
This project (git repo) is designed to handle document parsing and utilization for question answering with large language models (LLMs) on a local device. The process involves:
Document Parsing: Parsing provided documents into manageable portions.
Text Chunking: Breaking down the parsed document into discrete text chunks.
Vectorization: Converting each text chunk into an embedding vector stored in a FAISS vector database.
Prompting: Using the query embeddings to search the vector database and retrieve the top-k closest matching chunks.
LLM Question Answering: Feeding the retrieved chunks as prompts to an LLM model (llama.cpp) to generate accurate answers.
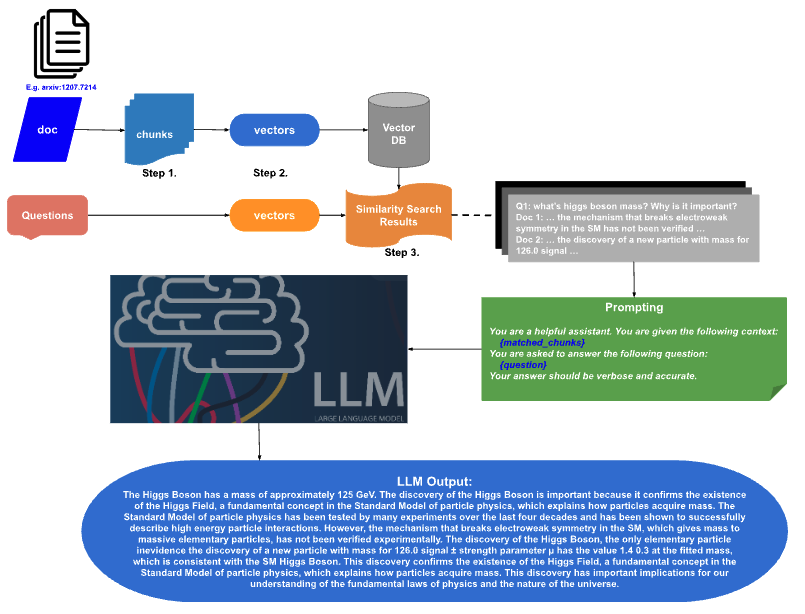 The flow chart for document parsing and question-answering with local LLMs
The flow chart for document parsing and question-answering with local LLMs
Why This is Interesting
Developing a local system for document parsing and question answering with LLMs is an intriguing endeavor for several reasons:
Privacy and Security
By keeping sensitive documents on-premises and avoiding uploading them to online servers, this system ensures robust privacy and security. This is crucial for handling confidential information across various domains like healthcare, finance, and legal.
Cost Efficiency
Running LLMs and associated services locally eliminates recurring costs from cloud providers, making it a cost-effective solution, especially for long-term usage.
Educational Value
This project serves as an excellent learning resource, providing insights into cutting-edge techniques like document chunking, text embeddings, vector databases, and LLM prompting. Students and enthusiasts can experiment hands-on with these technologies.
Customization and Control
A local deployment allows for greater customization and control over the entire pipeline, from document ingestion to model serving. This flexibility enables tailoring the system to specific use cases and requirements.
Scalability
By leveraging containerization with Docker, this system can be scaled horizontally across multiple machines, enabling efficient handling of large document corpora.
Use Cases
Some key use cases where this local LLM system could be beneficial include:
- Enterprises: Handling internal documents, reports, and knowledge bases securely.
- Research Institutions: Analyzing scientific literature and technical papers locally.
- Legal Firms: Querying over case files and legal documents with privacy guarantees.
- Educational Settings: Providing a hands-on learning environment for NLP and LLM technologies.
The combination of privacy, cost-efficiency, and flexibility makes this project appealing across various domains.
Tools and Technologies
The project utilizes the following tools and technologies:
- Docker for containerization
- Unstructured for text chunking
- FAISS as the vector database
- Langchain for FAISS integration
- Llama.cpp for serving the LLM
- TheBloke in Huggingface for quantized LLM models
Setup
Private Network with Docker
Multiple Docker containers communicate via a private network created with:
docker network create my-network
docker network ls
Document Chunking with Unstructured
Build Unstructured Docker Image:
docker pull downloads.unstructured.io/unstructured-io/unstructured:latest
cd docker
source build_docker.sh
Build Unstructured Container:
source scripts/build_container.sh
Document Partitioning and Chunking:
docker exec -it myunstructured bash -c "python3 src/document_partition.py -i [INPUT] -o [OUTPUT]"
docker exec -it myunstructured bash -c "python3 src/chunking.py -i [INPUT] -o [OUTPUT]"
Note: This step is optional.
Search via FAISS:
docker exec -it myunstructured bash -c "python3 src/vector_store.py -i [INPUT] -q \"QUESTION\""
Note: This step is optional.
RAG with Pretrained LLM
Build LLM Container:
models_folder=${FOLDER_OF_LLM_MODEL}
model_file=${LLM_MODEL_FILE}
container_name=llamacpp_server
docker run -dt --name ${container_name} -p 8080:8080 \
-v ${models_folder}:/models --network my-network \
ghcr.io/ggerganov/llama.cpp:server -m /models/${model_file} \
-c 512 --host 0.0.0.0 --port 8080
Question Answering:
llamacpp_container_name=llamacpp_server
docker exec -it myunstructured bash \
-c "python3 src/chatbot.py
-u http://${llamacpp_container_name}:8080/completion
-i INPUT_FILE -q \"QUESTION\""
Note it is a long string following the -c tag.
Example
llamacpp_container_name=llamacpp_server
docker exec -it myunstructured bash
-c "python3 src/chatbot.py
-u http://${llamacpp_container_name}:8080/completion
-i input/1207.7214.pdf -q \"What is the mass of the Higgs
Boson? Why is this discovery important?\""
This runs question answering on the paper “Observation of a New Particle in the Search for the Standard Model Higgs Boson with the ATLAS Detector at the LHC”, retrieving relevant chunks and generating an answer with the LLM.